Is the default response to work out something we already understand, or Google it regardless?
I have many email accounts. Some with spam and virus filters, some without, some personal, some for business, some as redirects from a couple of blogs I maintain, and so on. For the latter, I happened to notice, without much thought, that I had fewer spam messages where a captcha was employed from those that did not. I asked myself about ways of reducing spam and without thinking caught myself searching out effective options for reducing spam. I also did not need to type anything into a search engine, I already knew about OCR and putting my email address into jpeg to avoid scraping email addresses from text, I already knew about captchas, I already knew about spam filters and secondary or tertiary email addresses, but I caught myself on a search engine educating myself about what others had reported. Basically I was just browsing or, put another way, wasting time. Effectively browsing, searching, researching is also a researchers approach, but it is also so ignorant – avoiding spam is a solved problem and most search engine hits were nothing more than verbiage and marchitecture – research, mainly charts showing the types of spam, their geo-origin, time of quarantine, number of messages, some content semantics, all summarised with a bit of superficial discussion regarding the effectiveness of some organisations revolutionary product with buzzwords thrown in for search engine optimisation, AI, whitelist, adaptive, neural network, and so on (bullshit bingo). Almost always, these commercial entities also attempt to lure you in with offers of a no obligation demo and a bunch of other entrapments for something (who knows … sometimes what the organisation is attempting to sell isn’t even disclosed) to sucker you down yet another hole.
I already had an uninformed but intuitive train of thought regarding how bots harnessed email addresses for the purposes of distributing spam. Firstly it was obvious to me that I did not require information from a third party with their commercial motives. I had the general nous and technical skills to conduct an experiment and capture the minimal details I required (that also raises the most delicious question of whether I even needed further information). After all, the information I required did not need to be comprehensively granular. All I needed was a better feel for the subject matter. Maybe. Everyone, after all, understands spam, just as we understand email, how we communicate with a friend using a mobile phone, how we post something snail-mail and it arrives at the recipients address in the letterbox, etc. Secondly, and as a software developer, now, this experiment offered a leisurely way to spend a Sunday afternoon, and using technologies that were also outside my primary technical skill set to spice things up a little.
So, what did I consider, now that I have accepted I was going to going to waste a Sunday afternoon on arguably a pointless exercise? How were email addresses used for the purposes of spam harvested? Without much thinking, I decided that I should create a bunch of ephemeral email addresses, with a lifespan at most of of a couple of months or so, and broadcast them as text, in images, etc., on social media sites. Without even conducting an experiment, my intuition was to believe that if I were to publish the email address mike808@strychnine.co.uk on Instagram, Twitter, Facebook and so on, that I would quickly be in receipt of a deluge of spam, whereas if I were to publish an image containing an email address, that I would be in receipt of just a few spam messages. This just has to be correct, doesn’t it, after all “I read it on the internet”.
The Experiment
I created a whole bunch of disposable email addresses. The following shell script is typical
for i in mike892 mike428 mike348 mike384 mike438 mike483 mike834 mike843 mike587
do
deluser ${i}
rm -r /srv/strychnine.co.uk/mailboxes/${i}
useradd -m ${i} -s /bin/nologin
mkdir /srv/strychnine.co.uk/mailboxes/${i}
chown email:email -R /srv/strychnine.co.uk/mailboxes/${i}
done
The example above creates 8 dummy self hosted email addresses containing mike and the digits 8, 3, and 4 to generate some digit permutations of mike834@strychnine.co.uk (the intention was to provide the same digits for OCR, and avoid confusion between characters). The intention was to drop these email addresses into a jpeg of various sizes, background colours, text orientation, fonts, caps lock, ….. on social media sites.
Using DummyImage, this time without a loop, I generated some images with consistent background colours, and a few sizes. I manually created others with photos in the background too, to exercise the OCR behind the spambots.
curl "https://dummyimage.com/200x20/000/0011ff.jpg&text=mike348@strychnine.co.uk" > "mike348.jpg" curl "https://dummyimage.com/200x20/fff/0011ff.jpg&text=mike384@strychnine.co.uk" > "mike384.jpg" curl "https://dummyimage.com/200x20/fff/0011ff.jpg&text=MIKE438@STRYCHNINE.CO.UK" > "mike438.jpg" curl "https://dummyimage.com/200x20/000/000fff.jpg&text=mike834@strychnine.co.uk" > "mike834.jpg" curl "https://dummyimage.com/200x20/fff/000fff.jpg&text=mike843@strychnine.co.uk" > "mike843.jpg" curl "https://dummyimage.com/400x40/fff/000fff.jpg&text=mike483@strychnine.co.uk" > "mike483.jpg"
To avoid unnecessary detail, I confused the images with coloured backgrounds not readable to the human eye (black writing on a dark brown background) and posted on a number of different social media sites with topical hashtags to ensure I would create a few impressions and be picked up by the spambots. A partial screenshot from one of my Twitter accounts is shown below that should give a flavour of the general approach. Note too that the first Tweet also has an email address in plain text, no OCR would be required, and any automated IT system listening on a trending hashtag would have effortlessly pulled out the email address using a trivial regex.
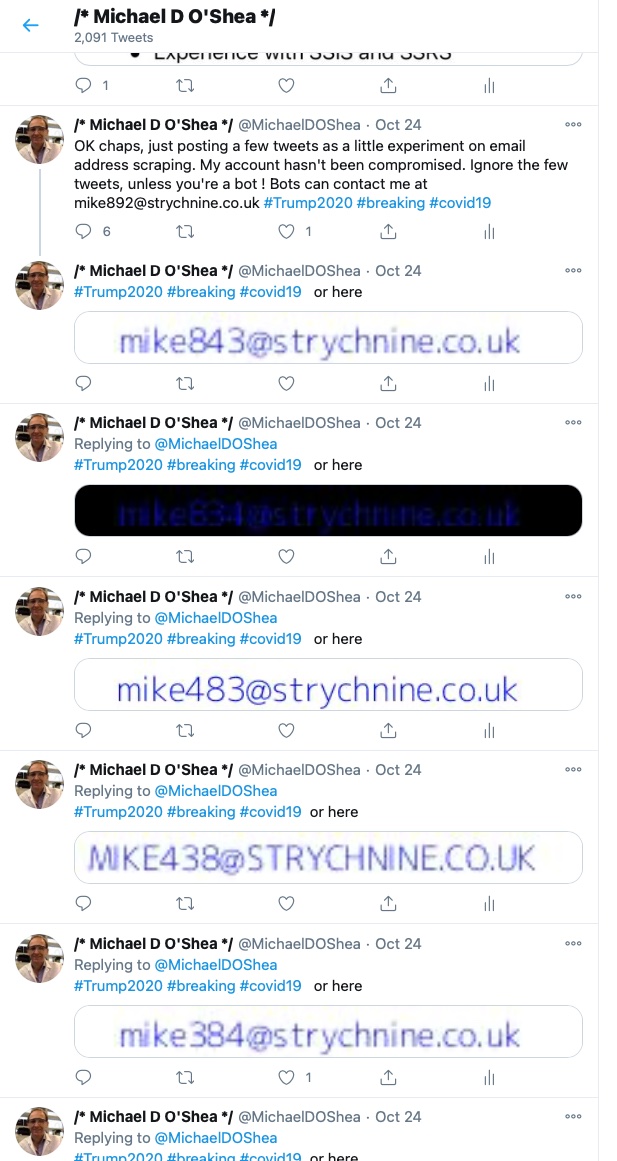
The Experimental Results
The experiment results are rather deflating. Over a collective period of just under 3 months, the aggregated results rounded to the nearest 10 messages are:
- Email address as text/ASCII: The total number of spam email messages received, 2630
- Email address in image, high contrast between foreground and background colours, eg. black or blue writing on white background, with image sizes of 200×20 and 400×40 pixels, 2140 (average of the two, both values similar magnitude)
- Email address in image, low contrast between foreground and background colours, eg. brown writing on black background, with image sizes of 200×20 and 400×40 pixels, 2170 (average of the two, both values similar magnitude)
- Email address in image, high contrast between foreground and background colours, email address orientated diagonally, image size 800×80 pixels, 2060
- Email address in image, blue text on a background image extracted from a news website (black text on a white background), image size 400×40 pixels, 810
- Email address (control experiment) where the email address was not published anywhere but was of the same format, ie. mike followed by some digits @strychnine.co.uk, 30
Clearly you cannot extract fine detail from aggregated data, and clearly the approach is multivariate but also sparse, but also my expectations are both right and wrong about how the spam recipient is targeted.
The results fall inline with my initial expectations.
- Email addresses published as text are easily captured and resulted in the largest number of spam messages received
- Email addresses as an image, a jpeg, where the background is a single solid colour, and irrespective of contrast between the foreground and background colour, or whether the email address is oriented horizontally or vertically, are (likely to be) picked out by OCR and resulted in a large number of spam messages received
- If OCR is being used to retrieve the email addresses from the image, as opposed to a mechanical turk for example, complex backgrounds in images have some success in reducing text extraction and the contrast between the foreground and background colours appears to make little difference.
Lastly, the control experiment is interesting. I received 30 email messages to an email account that I created on my MTA host, where I did not disclose this email address on any social media. The control experiment is also deficient. I should have created email addresses with the regular format, ie. mike followed by some digits @strychnine.co.uk, but also some email addresses that did not follow this regular format. I have no way of differentiating between the spam sent by bots speculatively from those that have some sort of underlying rule, that can see the regular format of mike1234@strychnine.co.uk, and test mike 1235, 1236, 1237, 1238, 1239 …. @strychnine.co.uk. In effect, the basic experiment design is flawed, but still succeeds in providing me with a feel for the subject matter. After all, I am after a feel for the subject matter and an approach this naive would be rejected from any serious journal in the primary literature.
Conclusion
Receiving spam after publishing an email address on social media is unsurprising. Given that the vast majority of these email addresses are harvested using optimised automated systems, it is also unsurprising that an email address can be harvested where a) it is disclosed as ASCII, b) disclosed within a jpeg oriented vertically or horizontally or where there is high or low contrast between the foreground and background colours. The exercise conducted was also far from thorough and my assumptions are supported from very limited data. Importantly however, and this is the crux of my blog post, I did not have to search out this information with a simple web search, and then believed what were served up to me as the top hit or two. I conducted this small unscientific experiment myself using ubiquitous technologies such as social media, email, and a bit of bash scripting. Almost anyone can do this, but almost anyone does not. The answer to the question at the top of this blog post is not just a parrot back the top hit Google (that may or may not have been correct and may or may not have had commercial other bias), but to work something out for myself. One of my conclusions from this small exercise is that I still frequently work out things for myself, more so if it is a bit of fun too, and I might be right or wrong but so might the top hit from Google or Bing written by … well who knows. The bottom line, you don’t need to Google everything, and sometimes nothing!
Oh, and in closing, mike843@strychnine.co.uk, and the other 300 or so email addresses I created for this experiment, now have all email redirected to /dev/null
Published by Mike, 13:25:53 11 Nov 2020 (GMT)
Archive
By Month: November 2022, October 2022, August 2022, February 2021, January 2021, December 2020, November 2020, March 2019, September 2018, June 2018, May 2018, April 2018
Categories
Apple, C#, Databases, Faircom, General IT Rant, German, Informatics, LINQ, MongoDB, Oracle, Perl, PostgreSQL, SQL, SQL Server, Unit Testing, XML/XSLT
Leave a Reply