Chemical Structures in Databases (blog article 7 of 8) : Under The Bonnet
As the SQL feature set doesn’t provide for chemical structures to be queried directly as shown below, the chemical moiety must first be translated into an alternative format supported by the DBMS. Typically the DBMS data type chosen is text VARCHAR, CHAR or unstructured data types such as a CLOB or BLOB. COTS examples of textual representations of chemical structures or reaction schemes include .mol or .rxn files, SMILES strings, and so on.

Under the bonnet within the extensible indexing component, these representations are decomposed into small collections of numbers, a fingerprint if you like. When a chemical database is searched for a specific chemical structure or substructure, this search structure is decomposed into a further set of numbers using the same algorithm. The database is then searched for matching number pairs using a DBMS language, eg. SQL, PL/SQL, T-SQL in possible combination with other logic implemented in C, C++ etc. within the extensible indexing component.
The UK National Lottery
Consider half a dozen or so numbers between 1 and 40. The numbers you choose will most likely be different to the numbers chosen by friends, family, work colleagues, or the roll of a tetracontagonal die. For draw 103 January 2006, the National Lottery Euro Millions draw rolled over for several weeks. In the process hundreds of millions of tickets were purchase and the estimated jackpot rose accordingly. Punters just had to d ecide on their numbers and purchase a ticket. Once the lottery had been drawn, everyone that held tickets with the same set of numbers as determined during the draw would have been entitled to share the estimated jackpot of £125 million Sterling (at the time, around €184 million, $330 million NZ)! Many chemical database systems work in very much in the same way. Chemical entities within the database will have been reduced to a small set of numbers when first populated into the database. Prior to querying the chemical database, the chemical entity being sought is reduced to a further small set of numbers using the same algorithm. The underlying SQL query executed matches the number pairs, those derived from the chemical entity being sought against those already in the database. This latter process is very much like searching a database containing all lottery ticket numbers against those determined during the lottery draw. For a database chemical structure search, there may be multiple rows returned (joint jackpot winners). When the result set contains no rows, the chemical entity is not in the chemical database (the jackpot rolls over). By reducing a chemical entity to a handful of numbers, the DBMS can quickly locate candidates that match initial search criteria. The candidate subset retrieved, possibly representing only one or two chemical entities out of hundreds of millions, can then evaluated with scrutiny to determine whether they match other search criteria not defined within the number set. This latter process is generally more expensive to perform than the initial query (see Subgraph Isomorphism). For this reason this more refined search is better performed on a candidate result set of a few, not hundreds of millions!
ecide on their numbers and purchase a ticket. Once the lottery had been drawn, everyone that held tickets with the same set of numbers as determined during the draw would have been entitled to share the estimated jackpot of £125 million Sterling (at the time, around €184 million, $330 million NZ)! Many chemical database systems work in very much in the same way. Chemical entities within the database will have been reduced to a small set of numbers when first populated into the database. Prior to querying the chemical database, the chemical entity being sought is reduced to a further small set of numbers using the same algorithm. The underlying SQL query executed matches the number pairs, those derived from the chemical entity being sought against those already in the database. This latter process is very much like searching a database containing all lottery ticket numbers against those determined during the lottery draw. For a database chemical structure search, there may be multiple rows returned (joint jackpot winners). When the result set contains no rows, the chemical entity is not in the chemical database (the jackpot rolls over). By reducing a chemical entity to a handful of numbers, the DBMS can quickly locate candidates that match initial search criteria. The candidate subset retrieved, possibly representing only one or two chemical entities out of hundreds of millions, can then evaluated with scrutiny to determine whether they match other search criteria not defined within the number set. This latter process is generally more expensive to perform than the initial query (see Subgraph Isomorphism). For this reason this more refined search is better performed on a candidate result set of a few, not hundreds of millions!
Why does it have to be this complicated?
I understand that SQL doesn’t allow me to search chemical structures directly, but why do I need all these numbers? Why can I just not search the chemical database for a molecular formula, relative molecular weight, or chemical name?
- Why not solely use the relative molecular weight to retrieve the chemical entity?
 |
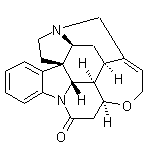 |
 |
| Brucine | Strychnine | Penicillin G |
To perform an exact structure search, a query on a chemical database for strychnine, the molecular formula is not sufficient to guarantee that the result set will contain strychnine and strychnine alone. For example, strychnine has a relative molecular weight of 334.42g/mol, as does penicillin G. Despite the relative molecular weights being the same, the chemical structures are clearly very different and both would be returned in the database resultset if the molecular weight alone were used as the sole key for chemical entity identification. The relative molecular weight can be useful in reducing the candidate result set, but other refine criteria would also be required. The relative molecular weight would also not that useful when performing a substructure search or search on the salts of strychnine. For example, the relative molecular weight would be of limited use in querying a chemical database for entities that contain strychnine as a sub-structure, eg. brucine. Brucine has a relative molecular weight of 394.47g/mol.
- Why not just use the molecular formula to retrieve the chemical entity?

The simple hydrocarbon heptane has a molecular formula of C7H16. Nine different isomers of heptane are shown above, and more exist. Strychnine has the molecular formula C21H22N2O2, along with many other known and unknown chemical entities! Like the relative molecular weight, the molecular formula alone cannot usefully be used as an identifying feature for a specific molecular entity.
- Why not just search on chemical name?
Use of the chemical name, or parts of it, as an identifying key in chemical database queries is not reliable. Any attempt to search a chemical database for chemical entities that contain an unsaturated normal linear chain of six carbon units, which includes n-heptane show above, would yield no hits for the search term “hexan” for example. Very clearly there are 6 carbon atoms in a linear chain in n-heptane yet chemical candidates would not be returned in the database resultset.
The Extensible Indexing Component
Within the extensible indexing component of the chemical database system, the chemical structure in question is first decomposed into predefined numbers, allowed values for the purposes of database indexing. For card based indexing systems, these categories could be a hole in a Cope-Chat card. In practice the number of categories would be in the range 20-80. A non exhaustive list of typical categories is shown below for Strychnine, Brucine, and Penicillin G. The numbers shown under the column headers Brucine, Strychnine, and Penicillin G for category ID’s 1 through 9 are the frequency of occurrence of the column header functional group (eg. brucine has 3 ether functional groups where Strychnine and Penicillin G have 1 and 0 respectively).
| Category ID | Category | Brucine | Strychnine | Penicillin G |
| 1 | Ether | 3 | 1 | 0 |
| 2 | Sulfide (thioether) | 0 | 0 | 1 |
| 3 | Amide | 1 | 1 | 2 |
| 4 | 1o Amine | 0 | 0 | 0 |
| 5 | 2o Amine | 0 | 0 | 0 |
| 6 | 3o Amine | 1 | 1 | 0 |
| 7 | 4o Amine | 0 | 0 | 0 |
| 8 | Thiol (mercaptan) | 0 | 0 | 0 |
| 9 | Ester | 0 | 0 | 0 |
| 10 | Maximum ring size | 7 | 7 | 6 |
| 11 | Minimum ring size | 5 | 5 | 4 |
| 12 | Number of rings | 7 | 7 | 3 |
| 13 | Number of heterocyclic rings | 3 | 3 | 2 |
| 14 | Relative molecular mass | 394.47 | 334.42 | 334.42 |
Adding a new chemical structure to the database
Extensible technology such as Oracle Data Cartridges typically fire an event for each relational database operation performed such as SQL SELECT, INSERT, UPDATE, or DELETE (named a CRUD operation), or DDL operations such as DROP, CREATE etc.
When a chemical structure is added to the database, ultimately using an SQL INSERT or UPSERT/MERGE statement, an event is fired to allow the extensible indexing DBMS component to update its indexes for the row being inserted. This event is not a database TRIGGER. Triggers are fired for only some database operations such as INSERT, DELETE, and UPDATE; they are not fired for SELECT, DROP etc. Within the event handling code, these numbers are generated from the chemical entity being inserted vide supra.
When Strychnine is first inserted into the chemical database system, the extensible component would have to:
- determine the native format data type such as a SMILES String, ChemDraw, or even one of the many products from ChemAxon/Marvin.
- reverse engineer the native format in a chemically aware manner to a representation suitable for fast searching, eg. an adjacency matrix.
- search the adjacency matrix for these known predetermined functional groups [eg. the number of ether functional groups is 1, the number of thiols is 0, the number of amides is 1) and other information (eg. the relative molecular weight (334.42g/mol), the number of hetereocyclic rings (3)].
- store and index this information for latter use in performant database queries vide infra.
In Summary: Searching a chemical structure database
- The following SQL pseudocode clearly demonstrates the requirements, to search a database table containing chemical structure information for Strychnine.

- The chemical structure of Strychnine is first converted to a data type supported by the DBMS, eg. a SMILES string. For brevity, only part of the SMILES string for Strychnine is shown below. The SMILES string is passed as an argument to a database operator or PSM.

- Within the extensible indexing component, the SMILES string is converted to an adjacency matrix.
- The adjacency matrix is searched for the presence and number of all predefined substructures or functional groups, eg. ether, thiol, amide etc; calculation of relative molecular weight etc. (in the example below, the explicit implication is that each predefined functional group etc. is represented by an additional database column containing this precalculated data in a very wide table. In any serious chemical database implementation, the approach is unlikely to be implemented in this manner. It does however simply convey the underlying operation performed).

- The adjacency matrix for Strychnine is compared against the adjacency matrix for each chemical entity represented by MoleculeID returned from the candidate database resultset returned above.
Each graph isomorph is a database hit for an exact structure search. Each adjacency matrix comparison that does not exactly match is not processed further and through the DBMS callback implementation of the extensible indexing component, is not included in the final database resultset.
For a substructure search, such as searching a chemical database for strychnine-like compounds such as Brucine, or other base structures endowed with various R-groups or open valencies, each subgraph isomorph is a database hit. As before these hits are returned through the DBMS callback implementation of the extensible indexing component to be included in the final database result set.
This is the seventh of eight blog articles with a subtitle of “Chemical Structures In Databases”. The prior article can be located here and the final article is in preparation.
— Published by Mike, 22:11:53 11 März 2019 (CET)
Archive
By Month: November 2022, October 2022, August 2022, February 2021, January 2021, December 2020, November 2020, March 2019, September 2018, June 2018, May 2018, April 2018
Categories
Apple, C#, Databases, Faircom, General IT Rant, German, Informatics, LINQ, MongoDB, Oracle, Perl, PostgreSQL, SQL, SQL Server, Unit Testing, XML/XSLT
Leave a Reply