The struggle of Software Requirements: Mass Spectrometry EIC Peak Aggregation vs. Time
Software developers have to endure many recurring frustrations. One of my pet hates is having to trawl through software requirement documents bloated out with pages of boilerplate crap, done seemingly as part of some templated workflow or quality assurance or regulatory process. It is not unusual for a Hello World requirements document to include a stock cover page with glossy image, empty revision history, abbreviations, and references/citations tables, index, ToC sections, and so on, to weigh in at around 15 pages before any useful content is added. The value in all of this content to the software developer is …. well there just so little value.
For a certain type of person, and I am one of those types, and more-so now as I am becoming a grumpy-old-man, is the frustration is having to trawl through this crap hunting for the actual software and/or user requirement. At times I am satisfied to find even a clue as to what is really required. It is just such a waste of everyones time.
Dealing with scientists close-to-the-lab is always a pleasure. There is something within a scientist that makes them document things clearly, succinctly, and by-example. Furthermore, I think it is neither training nor education and I proffer it may even be a genetic trait. Two analytical scientists I worked with a few years ago detailed a scientific requirement to me, in a language that I understood, they understood, and even some project managers understood, that unambiguously detailed the requirements. The requirements were detailed by worked examples punctuated by a few small sentences of clarification. One small piece of clarification text summarising the requirement is included inline below:
In a 3D Mass Chromatogram for an LCMS acquisition run
Forall nominal masses between some upper and lower bound
Foreach EIC peak picked for the nominal mass
Collate a set of corresponding LC peak retention times
Pivot then merge (with a small tolerance on the peak retention time)
Producing a table of LC retention times and the nominal masses observed
As a further lead in to the requirement, I show a typical screenshot from Waters Empower with an EIC slice at 464 mass units for a 3D MS channel (mouse click on the image to see it in higher resolution). Note the two peaks at 27.575 and 27.936min, and the masses at 262 and 464, and 464 mass units respectively (sic).
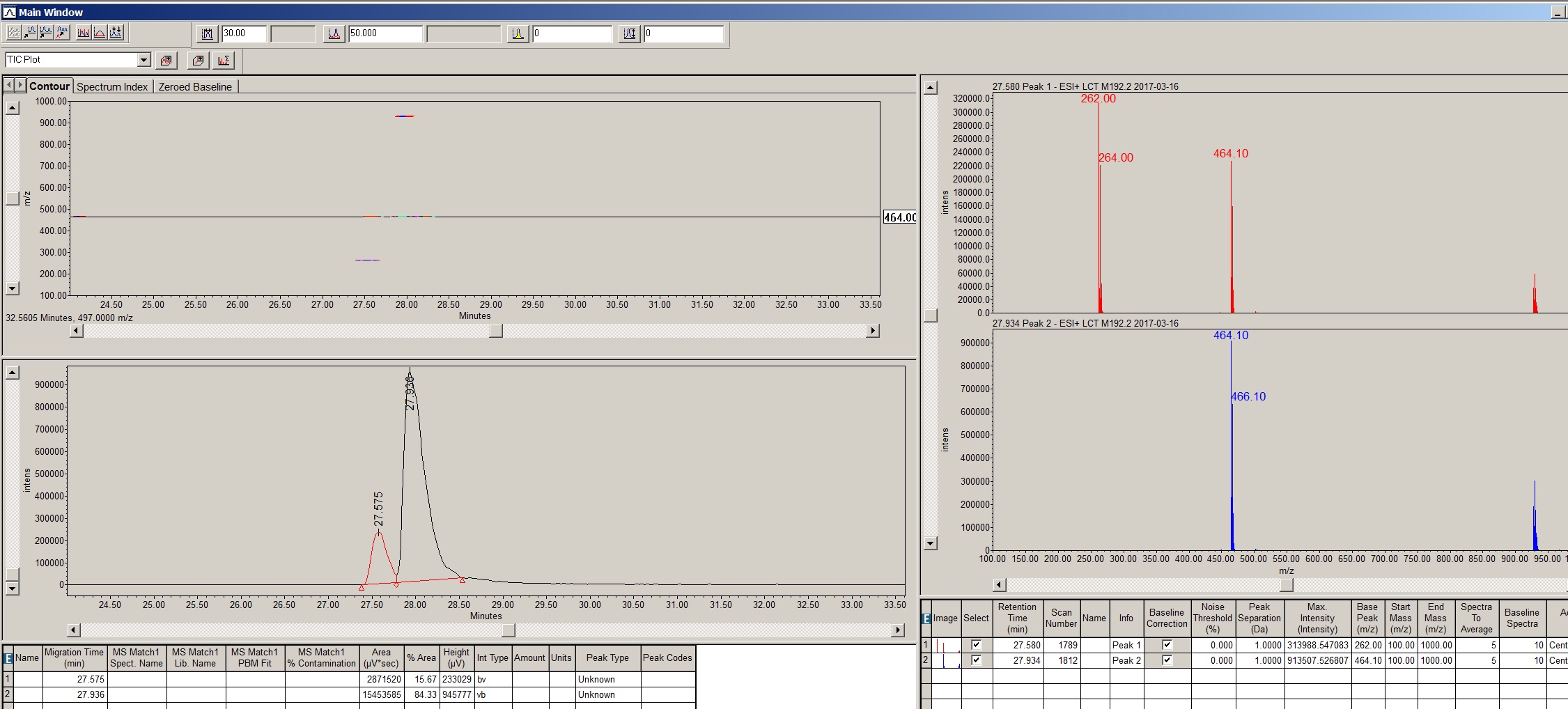
The ultimate requirement conveyed to me, for this exceptionally trivial 2/3 peak example, was to produce a table (as shown below) from 3D MS Chromatographic data.

A modern CDS as feature rich as Waters Empower already presents much of this information as out of the box functionality. The point is however that this type of detail is required for many chemoinformatic applications, and it was (then) required specifically for the purposes of LCMS component tracking using mass spectrometry as the primary analytical method, and that the custom software application software requirements were specified by-example.
So, with the software requirement described by-example, the question is specifically how to get from (a larger example set of contrived data) here:
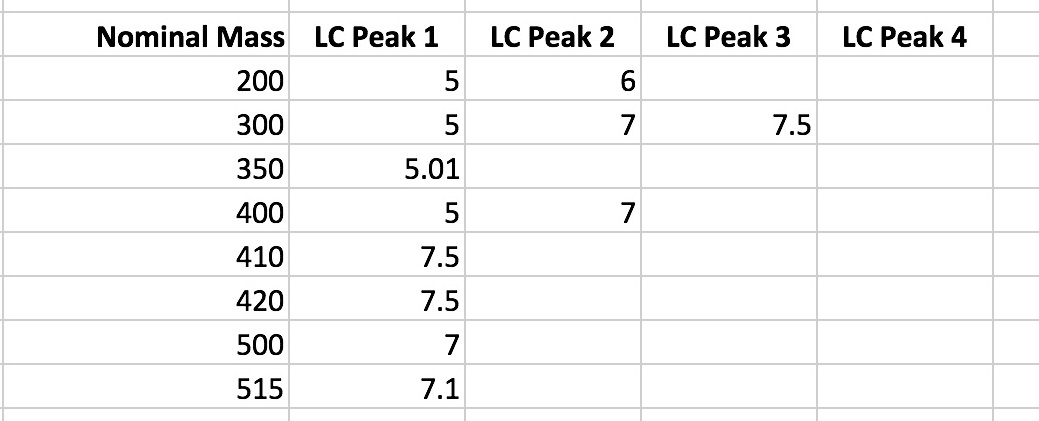
to here:

Note the table has been pivoted on nominal mass, and that some retention times have been merged (the peak at 5.01min with a nominal mass of 350 has been merged into the LC peak at 5min).
The answer to the question of how to
- specify the software requirements would be to write them down somewhere
- meet software requirements would be to cut some code
- confirm the code logic meets requirements and is not bugged would be to test it, ie. write some unit tests.
None of this is novel. What is perhaps novel is that the three answers to these three questions can all be written in-part by the scientist, business analyst, or project manager. Putting this another way, stake holders that are not software developers could write a large part of these software requirements, and they could be written by-example as an alternative to the pages of drivel typically found in many software requirements documents.
Q. Really?
A. Yes, really.
Q. What would this source code look like?
A. Transcribing the requirement described above, it would look like this.
Feature: Mass Spectrometry Peak Processing Background: Given I have an MS table containing the following peaks | Nominal Mass | LC Peak 1 | LC Peak 2 | LC Peak 3 | LC Peak 4 | | 200 | 5 | 6 | | | | 300 | 5 | 7 | 7.5 | | | 350 | 5.01 | | | | | 400 | 5 | 7 | | | | 410 | 7.5 | | | | | 420 | 7.5 | | | | | 500 | 7 | | | | | 515 | 7.1 | | | | Scenario: EIC Peak - pivoting of peak table (0.0min threshold check) When the tolerance is | LC Peak Merge Tolerance | | 0 | Then I expect the pivoted content | LC Retention Time | Mass 1 | Mass 2 | Mass 3 | Mass 4 | | 5 | 200 | 300 | 400 | | | 5.01 | 350 | | | | | 6 | 200 | | | | | 7 | 300 | 400 | 500 | | | 7.1 | 515 | | | | | 7.5 | 300 | 410 | 420 | | Scenario: EIC Peak - pivoting of peak table, LC peaks below threshold merge When the tolerance is | LC Peak Merge Tolerance | | 0.009 | Then I expect the pivoted content | LC Retention Time | Mass 1 | Mass 2 | Mass 3 | Mass 4 | | 5 | 200 | 300 | 400 | | | 5.01 | 350 | | | | | 6 | 200 | | | | | 7 | 300 | 400 | 500 | | | 7.1 | 515 | | | | | 7.5 | 300 | 410 | 420 | | Scenario: EIC Peak - pivoting of peak table, LC peaks at threshold merge (edgecase test) When the tolerance is | LC Peak Merge Tolerance | | 0.01 | Then I expect the pivoted content | LC Retention Time | Mass 1 | Mass 2 | Mass 3 | Mass 4 | | 5 | 200 | 300 | 350 | 400 | | 6 | 200 | | | | | 7 | 300 | 400 | 500 | | | 7.1 | 515 | | | | | 7.5 | 300 | 410 | 420 | |
Isn’t this source code easy to understand? Even if you don’t understand the scientific content, you can read and understand the logic and appreciate what the expected application inputs and outputs should be. This by-example approach is a way of specifying the requirements, and I repeat, without the pages of drivel so common in software requirements documents. In the code above, there are 3 examples, demonstrating both the input and expected output, that varies a little depending on how the content is pivoted and merged with a small tolerance value.
This language is … take a look at the SpecFlow website for further information. SpecFlow even offer an Excel addin, so the various scenario examples can be defined and tested in Excel on a laptop in an airplane or train and without input from a software developer! Additional test-case examples can be added to the by-example source code to further exercise the code logic and confirm the source code implementation meets requirements, for all the abstruse edge cases not included above.
The beauty of this approach is not only do the examples shown above define the requirements, but once the pivot logic is coded up and the tests plumbed in, they also define the Unit Tests (well obviously formally not Unit Tests, according to the definition, but please give me a bit of leeway here). For example (screenshot below), using the Continuous Integration (CI) Test Runner in Visual Studio, it can be seen that three Unit Tests have passed, as shown in the partial screenshot below. Confidence that the software developer has implemented what is required has to be high; the units test pass/fails are a sea of satisfying green!

My C# code implementation to perform the EIC peak/mass pivoting and merging is shown below:
using System;
using System.Collections.Generic;
using System.Linq;
namespace uk.co.woodwardinformatics.eic.peakpivot
{
public class EIC
{
public Dictionary<Decimal, List<int>> Pivot(Dictionary<int, List<Decimal>> massRetentionTimes, Decimal tolerance)
{
var retentionTimes = massRetentionTimes.Values.SelectMany(rt => rt).Distinct().OrderBy(rt => rt).ToList<Decimal>();
//pivot
var pivot = retentionTimes.ToDictionary(x => x, x => new List<int>());
foreach (var kvp in massRetentionTimes)
foreach (var retentionTime in kvp.Value)
pivot[retentionTime].Add(kvp.Key);
//put the retention times into buckets within the tolerance with first retention time in window
//being the boundary lower bound
var dict = new Dictionary<Decimal, Decimal>();
int currentDataPoint = 0;
while (currentDataPoint < retentionTimes.Count())
{
var rtBucket = from i in retentionTimes
let upperRetentionTimeBoundary = retentionTimes[currentDataPoint] + tolerance
where i <= retentionTimes[currentDataPoint] && i <= upperRetentionTimeBoundary
select new { BucketFirstRetentionTime = retentionTimes[currentDataPoint], MergeRetentionTime = i };
foreach (var x in rtBucket)
dict.Add(x.MergeRetentionTime, x.BucketFirstRetentionTime);
currentDataPoint += rtBucket.Count();
}
//coalesce/merge the retention times for the tolerance window
Dictionary<Decimal, List<int>> pivotMerge = new Dictionary<Decimal, List<int>>();
foreach (var rt in dict)
foreach (var mass in pivot[rt.Key])
{
if (!pivotMerge.ContainsKey(rt.Value))
pivotMerge.Add(rt.Value, new List<int>());
if (!pivotMerge[rt.Value].Contains(mass))
pivotMerge[rt.Value].Add(mass);
}
return pivotMerge;
}
}
}
The code behind to actually test this C# class is shown below too.
using NUnit.Framework;
using System;
using System.Collections.Generic;
using TechTalk.SpecFlow;
namespace uk.co.woodwardinformatics.eic.peakpivot
{
[Binding]
public class MassSpectrometryPeakProcessingSteps
{
private Dictionary<int, List<Decimal>> lookupPeakTable;
[Given(@"I have an MS table containing the following peaks")]
public void GivenIHaveAnMSTableContainingTheFollowingPeaks(Table table)
{
lookupPeakTable = new Dictionary<int, List<Decimal>>();
foreach (var dr in table.Rows)
{
int nominalMass = Convert.ToInt32(dr["Nominal Mass"]);
var lcRetentionTimes = new List<Decimal>();
for (int columnSuffix = 1; columnSuffix <= 4; columnSuffix++)
{
var retentionTime = dr[$"LC Peak {columnSuffix}"];
if (!String.IsNullOrEmpty(retentionTime))
lcRetentionTimes.Add(Convert.ToDecimal(retentionTime));
}
lookupPeakTable.Add(nominalMass, lcRetentionTimes);
}
}
private Decimal tolerance;
[When(@"the tolerance is")]
public void WhenTheToleranceIs(Table table)
{
tolerance = Convert.ToDecimal(table.Rows[0]["LC Peak Merge Tolerance"]);
}
[Then(@"I expect the pivoted content")]
public void ThenIExpectThePivotedContent(Table table)
{
var expectedRTmassTable = new Dictionary<Decimal, List<int>>();
foreach (var dr in table.Rows)
{
Decimal retentionTime = Convert.ToDecimal(dr["LC Retention Time"]);
var nominalMasses = new List<int>();
for (int columnSuffix = 1; columnSuffix <= 4; columnSuffix++)
{
var mass = dr[$"Mass {columnSuffix}"];
if (!String.IsNullOrEmpty(mass))
nominalMasses.Add(Convert.ToInt32(mass));
}
expectedRTmassTable.Add(retentionTime, nominalMasses);
}
var pivotedTable = new EIC().Pivot(lookupPeakTable, tolerance);
foreach (var expectedKVP in pivotedTable)
{
List<int> pivotedMasses = pivotedTable[expectedKVP.Key];
String err = $"Expected masses {String.Join(",",expectedKVP.Value)}, observed {String.Join(",", pivotedMasses)} for retention time {expectedKVP.Key}";
Assert.AreEqual(expectedKVP.Value.Count, pivotedMasses.Count, $"Pivoted mass count mismatch, {err}");
foreach (int mass in expectedKVP.Value)
Assert.IsTrue(expectedKVP.Value.Contains(mass), $"mass {mass} missing for retention time: {expectedKVP.Key}, {err}");
}
Assert.AreEqual(expectedRTmassTable.Count, pivotedTable.Count, "Pivoted EIC Retention Times/Masses");
}
}
}
Even if Mass Spectrometry and chemoinformatics are not your thing, the take home message is that the language of the software requirements specification, and the examples detailing input and output that define the unit tests, are human readable and can be specified in advance of the software developer cutting the code. Furthermore the BDD approach using SpecFlow specifies that the software designed and written will meet requirements, as the unadulterated software requirements double up as the Unit Tests/Software Requirements tests.
SpecFlow is now my fallback technology for writing both software requirements and Unit Tests. The fillip in the process is that writing software requirements is now writing code! The approach also ensures that what I deliver is what is specified, without the critical detail hidden embedded in a boilerplate requirements document somewhere (or, to put things another way, the requirements as specified using SpecFlow are part of the codebase and accompany the rest of the source code in Subversion, Git, or whatever). Also, and this is obvious but I am going to point it out too, the requirements specified using SpecFlow have to be up-to-date; if they are not, the Unit Tests performed against your code will fail (ie. the software requirements documentation and the code are synchronised, the software requirements do not become stale as the codebase is modified).
Some further information:
- In a prior blog article I also wrote a few notes on SpecFlow Cucumber for requirements definition
- PluralSight offer an online training course as an introduction to SpecFlow and dependent technologies
- The SpecFlow “in-IDE” test coverage/results above shows test coverage/issues using the Visual Studio (VS) Test Runner. Other “in-IDE” options are available too, and my favourite is NCrunch (not my favourite as it comes from New Zealand, but my favourite as it is the best product out there), a VS integrated addin providing interactive test coverage including IDE visual cues to indicate method coverage and test pass/fails
- Build server CI integration tools exist in abundance with notable modern COTS products that include Microsoft Team Foundation Server (TFS), JetBrains TeamCity, Jenkins and the like. Some very useful information on the background and objectives of CI can be found
- in an essay by Martin Fowler
- a blog article from Nutcache titled “A Simple Guide to Understanding Continuous Integration (CI)“
- a Wikipedia article.
— Published by Mike, 06:50:32 12 June 2017 (CET)
Archive
By Month: November 2022, October 2022, August 2022, February 2021, January 2021, December 2020, November 2020, March 2019, September 2018, June 2018, May 2018, April 2018
Categories
Apple, C#, Databases, Faircom, General IT Rant, German, Informatics, LINQ, MongoDB, Oracle, Perl, PostgreSQL, SQL, SQL Server, Unit Testing, XML/XSLT
Leave a Reply